In part 3 of this series we constructed a linear model in R to estimate the proportion of voters in the 2010 Howard County general election who are unaffiliated or members of other parties. (See also part 1 and part 2.) For our second prediction we’ll estimate the percentage of those voting who are Democrats. We’ll again make use of the lm() function, but this time we can make use of the fact that the result of lm() can be stored in a variable (which in this case we arbitrarily name lmd):
> lmd <- lm(hgg$PctVotersD ~ hgg$Year)
> lmd
Call:
lm(formula = hgg$PctVotersD ~ hgg$Year)
Coefficients:
(Intercept) hgg$Year
766.250 -0.358
>
Before we go on, note that the slope for the linear model for Democratic voters (-0.358) is almost equal in magnitude, but opposite in sign, to the slope for the linear model for unaffiliated and other voters (0.3522). Put more simply, the models seem to indicate that ongoing increases in the percentage of unaffiliated and other voters in Howard County gubernatorial general elections since 1990 are matched on average by corresponding decreases in the percentage of Democratic voters (presumably leaving the percentage of Republican voters relatively static).
As we did before, we can use the estimated slope and intercept to calculate an estimated value for the percentage of Democratic voters in the 2010 general election, assuming that the above trend continues:
> -0.358 * 2010 + 766.250
[1] 46.67
>
So 46.7% is our prediction for the percentage of voters who are Democrats, and as noted above 16.3% is our prediction for the percentage of unaffiliated and other voters. Subtracting the sum of these two values from 100 we obtain a prediction of 37.0% for the percentage of voters who are Republican.
Since we stored the linear model in the variable lmd we can do some additional analysis. First, we can compute what the predicted values of the percentage of Democratic voters would be based on the estimated linear relationship (using the predict() function), and compare that to the actual values:
> predict(lmd)
1 2 3 4 5
53.830 52.398 50.966 49.534 48.102
> hgg$PctVotersD
[1] 55.05 51.52 50.44 48.34 49.48
>
If we want to get fancier we can calculate the differences (or “residuals”) between the actual and predicted values:
> hgg$PctVotersD - predict(lmd)
1 2 3 4 5
1.220 -0.878 -0.526 -1.194 1.378
>
Note that since both hgg$PctVotersD and predict(lmd) contain five values, taking the difference between them produces five values as well.
So in general the actual and predicted values for the percentage of voters who are Democrats differ by about a percentage of the total vote. That likely means that our predicted value of 46.7% for 2010 could be off by at least that amount as well.
If we’d like more statistical goodness we can use the summary() function:
> summary(lmd)
Call:
lm(formula = hgg$PctVotersD ~ hgg$Year)
Residuals:
1 2 3 4 5
1.220 -0.878 -0.526 -1.194 1.378
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 766.2500 220.7716 3.471 0.0403 *
hgg$Year -0.3580 0.1105 -3.240 0.0479 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.398 on 3 degrees of freedom
Multiple R-squared: 0.7777, Adjusted R-squared: 0.7036
F-statistic: 10.5 on 1 and 3 DF, p-value: 0.04785
>
Some of these numbers we’ve seen before, including the slope, intercept, and residuals. Of the additional values, the most interesting for our purpose is the (multiple) R-squared value, which can be used as a measure of how well the linear model explains the observed data. More formally, the R-squared value (also known as the coefficient of determination) measures the proportion of the variability in the observed values that’s explained by the linear model. In this case the R-squared value of 0.7777 means that about three quarters of the variability in the observed data is explained by the linear model.1
This is a good but not great fit to the observed data. For another example let’s return to the linear model for the percentage of unaffiliated and other voters and look at the predicted values, residuals, and R-squared value:
> lmo <- lm(hgg$PctVotersOther ~ hgg$Year)
> predict(lmo)
1 2 3 4 5
9.374 10.783 12.192 13.601 15.010
> summary(lmo)
Call:
lm(formula = hgg$PctVotersOther ~ hgg$Year)
Residuals:
1 2 3 4 5
0.016 0.167 -0.122 -0.321 0.260
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -691.6035 42.1549 -16.41 0.000493 ***
hgg$Year 0.3523 0.0211 16.70 0.000468 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2669 on 3 degrees of freedom
Multiple R-squared: 0.9894, Adjusted R-squared: 0.9858
F-statistic: 278.7 on 1 and 3 DF, p-value: 0.0004678
>
Note that here the residuals are quite small (a fraction of a percent of the total vote) and the R-squared value is quite close to 1.0, indicating that the linear model explains almost all the variability in the observed data.2
Finally, let’s redo the graph from the last post to include trend lines for both the Democratic and independent proportions of the total voting population in gubernatorial elections since 1990:
> plot(hgg$Year, hgg$PctVotersR, xlim=c(1990, 2010), ylim=c(0, 60))
> points(hgg$Year, hgg$PctVotersD)
> points(hgg$Year, hgg$PctVotersOther)
> abline(coef(lmo))
> abline(coef(lmd))
>
Note that since we stored the linear models in the variables lmo and lmd we don’t have to manually type in the slope and intercept arguments (the “coefficients” of the line’s equation) to the abline() function. Instead we can simply use the coef() function to extract those coefficients and plug them in.
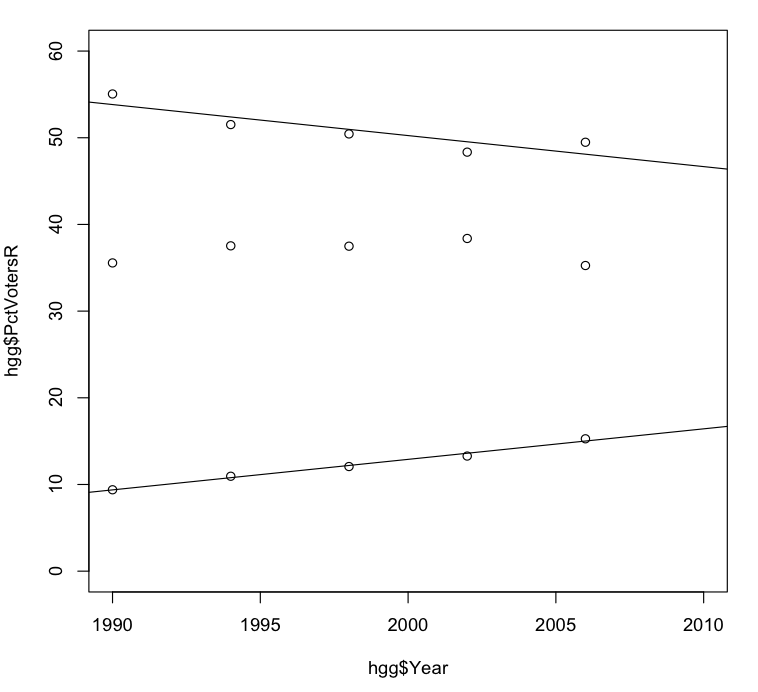
Statistics by themselves can take us only so far. We still have the question of why the proportion of unaffiliated and other voters seems to be increasing in such a strict linear manner from election to election. We also don’t know why the increase in the proportion of unaffiliated and other voters seems to be primarily affecting the proportion of Democratic voters and not (on average) the proportion of Republican voters.
I’ve already attempted an answer to the first question in a previous post. Regarding the second question, the graph above suggests that the proportion of Democratic voters may actually be about to grow again, and the proportion of Republican voters to decrease. If that turns out to be the case in the 2010 Howard County general election then our linear model for the Democratic proportion of voters may be wrong.
In the meantime in the next post I’ll look at another proposed approach to estimating the relative proportions of total voters from the two major parties and independents, this time using the data from past primary elections.
Note that we can easily compute the R-squared value as follows:
We first compute the variability in the observed data by taking the differences between the observed values and their mean:
> mean(hgg$PctVotersD) [1] 50.966 > hgg$PctVotersD - mean(hgg$PctVotersD) [1] 4.084 0.554 -0.526 -2.626 -1.48 >then squaring the differences and summing the squares:
> (hgg$PctVotersD - mean(hgg$PctVotersD))^2 [1] 16.679056 0.306916 0.276676 6.895876 2.208196 > sum((hgg$PctVotersD - mean(hgg$PctVotersD))^2) [1] 26.36672 >We then take the residuals (the differences between the actual values and the values predicted by the linear model), square them, and take the sum:
> hgg$PctVotersD - predict(lmd) 1 2 3 4 5 1.220 -0.878 -0.526 -1.194 1.378 > (hgg$PctVotersD - predict(lmd))^2 1 2 3 4 5 1.488400 0.770884 0.276676 1.425636 1.898884 > sum((hgg$PctVotersD - predict(lmd))^2) [1] 5.86048 >The ratio of these two numbers gives the proportion of variability in the observed data not explained by the linear model, which we can then subtract from 1 to give the proportion of variability explained by the model:
↩︎> 5.86048 / 26.36672 [1] 0.2222681 > 1 - 0.2222681 [1] 0.7777319 >Again we can easily calculate the R-squared value for ourselves:
↩︎> sum((hgg$PctVotersOther - predict(lmo))^2) [1] 0.21367 > sum((hgg$PctVotersOther - mean(hgg$PctVotersOther))^2) [1] 20.06648 > 1 - (0.21367 / 20.06648) [1] 0.9893519 >